
View: session overviewtalk overview
| 09:00 | Machine-Checked Proofs of Privacy Against Malicious Boards for Selene & Co PRESENTER: Peter B. Rønne ABSTRACT. Privacy is a notoriously difficult property to achieve in complicated systems and especially in electronic voting schemes. Moreover, electronic voting schemes is a class of systems that require very high assurance. The literature contains a number of ballot privacy definitions along with security proofs for common systems. Some machine-checked security proofs have also appeared. We define a new ballot privacy notion that captures a larger class of voting schemes. This notion improves on the state of the art by taking into account that verification in many schemes will happen or must happen after the tally has been published, not before as in previous definitions. As a case study we give a machine-checked proof of privacy for Selene, which is a remote electronic voting scheme which offers an attractive mix of security properties and usability. Prior to our work, the computational privacy of Selene has never been formally verified. Finally, we also prove that MiniVoting and Belenios satisfies our definition. |
| 09:30 | Universal Optimality and Robust Utility Bounds for Metric Differential Privacy PRESENTER: Catuscia Palamidessi ABSTRACT. We study the privacy-utility trade-off in the context of metric differential privacy. Ghosh et al. introduced the idea of universal optimality to characterise the ``best'' mechanism for a certain query that simultaneously satisfies (a fixed) $\epsilon$-differential privacy constraint whilst at the same time providing better utility compared to any other $\epsilon$-differentially private mechanism for the same query. They showed that the Geometric mechanism is universally optimal for the class of counting queries. On the other hand, Brenner and Nissim showed that outside the space of counting queries, and for the Bayes risk loss function, no such universally optimal mechanisms exist. Except for universal optimality of the Laplace mechanism, there have been no generalisations of these universally optimal results to other classes of differentially-private mechanisms. In this paper we use metric differential privacy and quantitative information flow as the fundamental principle for studying universal optimality. Metric differential privacy is a generalisation of both standard (i.e., central) differential privacy and local differential privacy, and it is increasingly being used in various application domains, for instance in location privacy and in privacy preserving machine learning. As do Ghosh et al. and Brenner and Nissim, we measure utility in terms of loss functions, and we interpret the notion of a privacy mechanism as an information-theoretic channel satisfying constraints defined by $\epsilon$-differential privacy and a metric meaningful to the underlying state space. Using this framework we are able to clarify Nissim and Brenner's negative results by (a) that in fact all privacy types contain optimal mechanisms relative to certain kinds of non-trivial loss functions, and (b) extending and generalising their negative results beyond Bayes risk specifically to a wide class of non-trivial loss functions. Our exploration suggests that universally optimal mechanisms are indeed rare within privacy types. We therefore propose weaker universal benchmarks of utility called privacy type capacities. We show that such capacities always exist and can be computed using a convex optimisation algorithm. Finally, we illustrate these ideas on a selection of examples with several different underlying metrics. |
| 10:00 | Unlinkability of an Improved Key Agreement Protocol for EMV 2nd Gen Payments PRESENTER: Semyon Yurkov ABSTRACT. To address known privacy problems with the EMV standard, EMVCo have proposed a Blinded Diffie-Hellman key establishment protocol, which is intended to be part of a future 2nd Gen EMV protocol. We point out that active attackers were not previously accounted for in the privacy requirements of this proposal protocol, and demonstrate that an active attacker can compromise unlinkability within a distance of 100cm. Here, we adopt a strong definition of unlinkability that does account for active attackers and propose an enhancement of the protocol proposed by EMVCo. We prove that our protocol does satisfy strong unlinkability, while preserving authentication. |
| 09:00 | Knowledge Extraction Based on Forgetting and Subontology Generation ABSTRACT. This presentation will give an overview of our ongoing work in developing knowledge extraction methods for description logic based ontologies. Because the stored knowledge is not only given by the axioms stated in an ontology but also by the knowledge that can be inferred from these axioms, knowledge extraction is a challenging problem. Forgetting creates a compact and faithful representation of the stored knowledge over a user-specified signature by performing inferences on the symbols outside this signature. After an introduction of the idea of forgetting, an overview of our forgetting tools and some applications we have explored, I will discuss recent collaborative work with SNOMED International to create bespoke knowledge extraction software the medical ontology SNOMED CT. The software creates a self-contained subontology containing definitions of a specified set of focus concepts which minimises the number of supporting symbols used and satisfies SNOMED modelling guidelines. Such subontologies make it easier to reuse and share content, assist with ontology analysis, and querying and classification is faster. The talk will give an overview of this research spanning several years, focussing on key ideas, findings, practical challenges encountered and current applications. |
| 10:00 | Next Steps for ReAD: Modules for Classification Optimisation  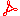 PRESENTER: Haoruo Zhao ABSTRACT. Ontology Classification is a central DL reasoning task and supported by several highly-optimised reasoners for OWL ontologies. Different notions of modularity, including the atomic decomposition (AD), have already been exploited by different modular reasoners. In our previous work, we have designed and implemented a new AD-informed and MORe-inspired algorithm that uses Hermit and ELK as delegate reasoners, but avoids any duplicate subsumption tests between these two reasoners. In this paper, we push the algorithm further with easyfication and parallelization. We empirically evaluate our algorithm with a set of Snomed CT extensions ontologies and a corpus of BioPortal ontologies. We also design, implement and empirically evaluate a new modular reasoner, called Crane, which works with ``coarsened'' AD. |
| 09:00 | CTL* model checking for data-aware dynamic systems with arithmetic PRESENTER: Sarah Winkler ABSTRACT. The analysis of complex dynamic systems is a core research topic in formal methods and AI, and combined modelling of systems with data has gained increasing importance in applications such as business process management. In addition, process mining techniques are nowadays used to automatically mine process models from event data, often without correctness guarantees. Thus verification techniques for linear and branching time properties are needed to ensure desired behavior. Here we consider data-aware dynamic systems with arithmetic (DDSAs), which constitute a concise but expressive formalism of transition systems with linear arithmetic guards. We present a CTL* model checking procedure for DDSAs that relies on a finite-state abstraction by means of a set of formulas that capture variable configurations. Linear-time verification was shown to be decidable in specific classes of DDSAs where the constraint language or the control flow are suitably confined. We investigate several of these restrictions for the case of CTL*, with both positive and negative results: CTL* verification is proven decidable for monotonicity and integer periodicity constraint systems, but undecidable for feedback free and bounded lookback systems. To witness the feasibility of our approach, we implemented it in the SMT-based prototype ada. It turns out that many practical business process models can be effectively analyzed by our tool. |
| 09:20 | Implicit Definitions with Differential Equations for KeYmaera X (System Description) PRESENTER: Yong Kiam Tan ABSTRACT. Definition packages in theorem provers provide users with means of defining and organizing concepts of interest. This system description presents a new definition package for the hybrid systems theorem prover KeYmaera X based on differential dynamic logic (dL). The package adds KeYmaera X support for user-defined smooth functions whose graphs can be implicitly characterized by dL formulas. Notably, this makes it possible to implicitly characterize functions, such as the exponential and trigonometric functions, as solutions of differential equations and then prove properties of those functions using dL's differential equation reasoning principles. Trustworthiness of the package is achieved by minimally extending KeYmaera X's soundness-critical kernel with a single axiom scheme that expands function occurrences with their implicit characterization. Users are provided with a high-level interface for defining functions and non-soundness-critical tactics that automate low-level reasoning over implicit characterizations in hybrid system proofs. |
| 09:35 | On eventual non-negativity and positivity for the weighted sum of powers of matrices PRESENTER: Supratik Chakraborty ABSTRACT. The long run behaviour of linear dynamical systems is often studied by looking at eventual properties of matrices and recurrences that underlie the system. A basic problem that lies at the core of many questions in this setting is the following: given a set of pairs of rational weights and matrices {(w1, A1), . . . , (wm, Am)}, we ask if the weighted sum of powers of these matrices is eventually non-negative (resp. positive), i.e., does there exist an integer N s.t for all n greater than N , (w1.A1^n + w2.A2^n+ ... + w_m.Am^n) \geq 0 (resp. > 0). The restricted setting when m = w1 = 1, results in so-called eventually non-negative (or eventually positive) matrices, which enjoy nice spectral properties and have been well-studied in control theory. More applications arise in varied contexts, ranging from program verification to partially observable and multi-modal systems. Our goal is to investigate this problem and its link to linear recurrence sequences. Our first result is that for m > 1, the problem is as hard as the ultimate positivity of linear recurrences, a long standing open question (known to be coNP-hard). Our second result is a reduction in the other direction showing that for any m \geq 1, the problem reduces to ultimate positivity of linear recurrences. This shows precise upper bounds for several subclasses of matrices by exploiting known results on linear recurrence sequences. Our third main result is an effective algorithm for the class of diagonalizable matrices, which goes beyond what is known on linear recurrence sequences. |
| 09:55 | Proving Non-Termination and Lower Runtime Bounds with LoAT (System Description) PRESENTER: Florian Frohn ABSTRACT. We present the Loop Acceleration Tool (LoAT), a powerful tool for proving non-termination and worst-case lower bounds for programs operating on integers. It is based on a novel calculus for loop acceleration, i.e., transforming loops into non-deterministic straight-line code, and for finding non-terminating configurations. To implement it efficiently, LoAT uses a new approach based on unsat cores. We evaluate LoAT's power and performance by extensive experiments. |
| 10:10 | Automatic Complexity Analysis of Integer Programs via Triangular Weakly Non-Linear Loops PRESENTER: Nils Lommen ABSTRACT. There exist several results on deciding termination and computing runtime bounds for triangular weakly non-linear loops (twn-loops). We show how to use such results on subclasses of programs where complexity bounds are computable within incomplete approaches for complexity analysis of full integer programs. To this end, we present a novel modular approach which computes local runtime bounds for subprograms which can be transformed into twn-loops. These local runtime bounds are then lifted to global runtime bounds for the whole program. The power of our approach is shown by our implementation in the tool KoAT which analyzes complexity of programs where all other state-of-the-art tools fail. |
| 09:00 | (Invited) User Interface Design in the HolPy Theorem Prover ABSTRACT. HolPy is a new interactive theorem prover implemented in Python. It is designed to achieve a small trusted-code-base with externally checkable proofs, writing proof automation using a Python API, and permit a wide variety of user interfaces for different application scenarios. In this talk, I will focus on the design of user interfaces in HolPy. While most interactive theorem provers today use text-based user interfaces, there have been several existing work aiming to build point-and-click interfaces where the user perform actions by clicking on part of the goal or choosing from a menu. In our work, we incorporate into the design extensive proof automation and heuristic suggestion mechanisms, allowing construction of proofs on a large scale using this method. We demonstrate the approach in two common scenarios: general-purpose theorem proving and symbolic computation in mathematics. |
| 10:00 | Accelerating Verified-Compiler Development with a Verified Rewriting Engine PRESENTER: Jason Gross ABSTRACT. Compilers are a prime target for formal verification, since compiler bugs invalidate higher-level correctness guarantees, but compiler changes may become more labor-intensive to implement, if they must come with proof patches. One appealing approach is to present compilers as sets of algebraic rewrite rules, which a generic engine can apply efficiently. Now each rewrite rule can be proved separately, with no need to revisit past proofs for other parts of the compiler. We present the first realization of this idea, in the form of a framework for the Coq proof assistant. Our new Coq command takes normal proved theorems and combines them automatically into fast compilers with proofs. We applied our framework to improve the Fiat Cryptography toolchain for generating cryptographic arithmetic, producing an extracted command-line compiler that is about 1000x faster while actually featuring simpler compiler-specific proofs. |
| 11:00 | Adversarial Robustness Verification and Attack Synthesis in Stochastic Systems PRESENTER: Lisa Oakley ABSTRACT. Probabilistic model checking is a useful technique for specifying and verifying properties of stochastic systems including randomized protocols and reinforcement learning models. However, these methods rely on the assumed structure and probabilities of certain system transitions. These assumptions may be incorrect, and may even be violated by an adversary who gains control of some system components. In this paper, we develop a formal framework for adversarial robustness in systems modeled as discrete time Markov chains (DTMCs). We base our framework on existing methods for verifying probabilistic temporal logic properties and extend it to include deterministic, memoryless policies acting in Markov decision processes (MDPs). Our framework includes a flexible approach for specifying structure-preserving and non structure-preserving adversarial models. We outline a class of threat models under which adversaries can perturb system transitions, constrained by an $\varepsilon$ ball around the original transition probabilities. We define three main DTMC adversarial robustness problems: adversarial robustness verification, maximal $\delta$ synthesis, and worst case attack synthesis. We present two optimization-based solutions to these three problems, leveraging traditional and parametric probabilistic model checking techniques. We then evaluate our solutions on two stochastic protocols and a collection of Grid World case studies, which model an agent acting in an environment described as an MDP. We find that the parametric solution results in fast computation for small parameter spaces. In the case of less restrictive (stronger) adversaries, the number of parameters increases, and directly computing property satisfaction probabilities is more scalable. We demonstrate the usefulness of our definitions and solutions by comparing system outcomes over various properties, threat models, and case studies. |
| 11:30 | The Complexity of Verifying Boolean Programs as Differentially Private PRESENTER: Ludmila Glinskih ABSTRACT. We study the complexity of the problem of verifying differential privacy for while-like programs working over boolean values and making probabilistic choices. Programs in this class can be interpreted into finite-state discrete-time Markov Chains (DTMC). We show that the problem of deciding whether a program is differentially private for specific values of the privacy parameters is PSPACE-complete. To show that this problem is in PSPACE, we adapt classical results about computing hitting probabilities for DTMC. To show PSPACE-hardness we use a reduction from the problem of checking whether a program almost surely terminates or not. We also show that the problem of approximating the privacy parameters that a program provides is PSPACE-hard. Moreover, we investigate the complexity of similar problems also for several relaxations of differential privacy: Rényi differential privacy, concentrated differential privacy, and truncated concentrated differential privacy. For these notions, we consider gap-versions of the problem of deciding whether a program is private or not and we show that all of them are PSPACE-complete. |
| 12:00 | Adversary Safety by Construction in a Language of Cryptographic Protocols PRESENTER: Alice Lee ABSTRACT. Compared to ordinary concurrent and distributed systems, cryptographic protocols are distinguished by the need to reason about interference by adversaries. We suggest a new layered approach to tame that complexity, via an executable protocol language whose semantics does not reveal an adversary directly, instead enforcing a set of intuitive hygiene rules. By virtue of those rules, protocols written in this language provably behave identically with or without interference by active Dolev-Yao-style adversaries. As a result, formal reasoning about protocols can be simplified enough that even naı̈ve model checking can establish correctness of a multiparty protocol, through analysis of a state space with no adversary. We present the design and implementation of SPICY, short for Secure Protocols Implemented CorrectlY, including the semantics of its input languages; the essential safety proofs, formalized in the Coq theorem prover; and the automation techniques. We provide a preliminary evaluation of the tool’s performance and capabilities via a handful of case studies. |
| 11:00 | Computing Concept Referring Expressions with Standard OWL Reasoners PRESENTER: Birte Glimm ABSTRACT. Classical instance queries over an ontology only consider explicitly named individuals. Concept referring expressions (CREs) also allow for returning answers in the form of concepts that describe implicitly given individuals in terms of their relation to an explicitly named one. Existing approaches, e.g., based on tree automata, can neither be integrated into state-of-the-art OWL reasoners nor are they directly amenable for an efficient implementation. To address this, we devise a novel algorithm that uses highly optimized OWL reasoners as a black box. In addition to the standard criteria of singularity and certainty for CREs, we devise and consider the criterion of uniqueness of CREs for Horn ALC ontologies. The evaluation of our prototypical implementation shows that computing CREs for the most general concept (⊤) can be done in less than one minute for ontologies with thousands of individuals and concepts. |
| 11:25 | Accessing Document Data Sources using Referring Expression Types PRESENTER: David Toman ABSTRACT. We show how JSON documents can be abstracted as concept descriptions in an appropriate description logic. This representation allows the use of additional background knowledge in a form of a TBox and an assignment of referring expression types (RETs) to certain primitive concepts to detect situations in which subdocuments, perhaps multiple subdocuments located in various parts of the original documents, capture information about a particular conceptual entity. Detecting such situations allows for normalizing the JSON document into several separate documents that capture all information about such conceptual entities in separate documents. This transformation preserves all the original information present in the input documents. The RET assignment contributes a set of possible concept descriptions that enable more refined and normalized capture of documents, and to more crafted answers to queries that adhere to user expectations expressed as RETs. We also show how RETs allow checking for a document admissibility condition that ensures that the documents describe a single conceptual entity. |
| 11:50 | Extraction of Object-Centric Event Logs through Virtual Knowledge Graphs PRESENTER: Diego Calvanese ABSTRACT. Data preparation is a key step for process mining. In this paper, we present how to leverage the Virtual Knowledge Graph approach for extracting event logs from data in relational databases. This approach is implemented in the OnProm system, and supports both the IEEE Standard for eXtensible Event Stream (XES), and the recently proposed standard Object-Centric Event Logs (OCEL).Process mining is a family of techniques that supports the analysis of operational processes based on event logs. Among the existing event log formats, the IEEE standard eXtensible Event Stream (XES) is the most widely adopted. In XES, each event must be related to a single case object, which may lead to convergence and divergence problems. To solve such issues, object-centric approaches become promising, where objects are the central notion, and one event may refer to multiple objects. In particular, the Object-Centric Event Logs (OCEL) standard has been proposed recently. However, the crucial problem of extracting OCEL logs from external sources is still largely unexplored. In this paper, we try to fill this gap by leveraging the Virtual Knowledge Graph (VKG) approach to access data in relational databases. We have implemented this approach in the OnProm system, extending it from XES to OCEL support. |
| 12:15 | Category-based Semantics for the Description Logic ALC and Reasoning PRESENTER: Ludovic Brieulle ABSTRACT. We present in this paper a reformulation of the usual set-theoretical semantics of the description logic ALC with general TBoxes by using categorical language. In this setting, ALC concepts are represented as objects, concept subsumptions as arrows, and memberships as logical quantifiers over objects and arrows of categories. Such a category-based semantics provides a more modular representation of the semantics of ALC. This feature allows us to define a sublogic of ALC by dropping the interaction between existential and universal restrictions, which would be responsible for an exponential complexity in space. Such a sublogic is undefinable in the usual set-theoretical semantics, We show that this sublogic is PSPACE by proposing a deterministic algorithm for checking concept satisfiability which runs in polynomial space. |
| 11:00 | Connection-minimal Abduction in EL via translation to FOL PRESENTER: Sophie Tourret ABSTRACT. Abduction is the task of finding possible extensions of a given knowledge base that would make a given sentence logically entailed. As such, it can be used to explain why the sentence does not follow, to repair incomplete knowledge bases, and to provide possible explanations for unexpected observations. We consider TBox abduction in the lightweight description logic EL, where the observation is a concept inclusion and the background knowledge is a description logic TBox. To avoid useless answers, such problems usually come with further restrictions on the solution space and/or minimality criteria that help sort the chaff from the grain. We argue that existing minimality notions are insufficient, and introduce connection minimality. This criterion rejects hypotheses that use concept inclusions “disconnected” from the problem at hand. We show how to compute a special class of connection-minimal hypotheses in a sound and complete way. Our technique is based on a translation to first-order logic, and constructs hypotheses based on prime implicates. We evaluate a prototype implementation of our approach on ontologies from the medical domain. |
| 11:20 | Decision Problems in a Logic for Reasoning about Reconfigurable Distributed Systems PRESENTER: Lucas Bueri ABSTRACT. We consider a logic used to describe sets of configurations of distributed systems, whose network topologies can be changed at runtime, by reconfiguration programs. The logic uses inductive definitions to describe networks with an unbounded number of components and interactions, written using a multiplicative conjunction, reminiscent of Bunched Implications and Separation Logic. We study the complexity of the satisfiability and entailment problems for the configuration logic under consideration. Additionally, we consider degree boundedness (is every component involved in a bounded number of interactions?), an ingredient for decidability of entailments. |
| 11:40 | Reasoning About Vectors using an SMT Theory of Sequences PRESENTER: Clark Barrett ABSTRACT. Dynamic arrays, also referred to as vectors, are fundamental data structures used in many programs. Modeling their semantics efficiently is crucial when reasoning about such programs. The theory of arrays is widely supported but is not ideal, because the number of elements is fixed (determined by its index sort) and cannot be adjusted, which is a problem, given that the length of vectors often plays an important role when reasoning about vector programs. In this paper, we propose reasoning about vectors using a theory of sequences. We introduce the theory, propose a basic calculus adapted from one for the theory of strings, and extend it to efficiently handle common vector operations. We prove that our calculus is sound and show how to construct a model when it terminates with a saturated configuration. Finally, we describe an implementation of the calculus in cvc5 and demonstrate its efficacy by evaluating it on verification conditions for smart contracts and benchmarks derived from existing array benchmarks. |
| 12:00 | Flexible Proof Production in an Industrial-Strength SMT Solver PRESENTER: Haniel Barbosa ABSTRACT. Proof production for SMT solvers is paramount to ensure their correctness independently from implementations, which are often prohibitively complex to be verified. However, historically SMT proof production has struggled with performance and coverage issues, with many crucial solving techniques being disabled, and lack of details, with hard to check, coarse-grained proofs. Here we present a flexible proof production architecture designed to handle the complexity of versatile, industrial-strength SMT solvers, and how we leveraged it to produce detailed proofs, including for previously unsupported components by any solver. The architecture allows proofs to be produced modularly, lazily and with numerous safeguards for correct generation. This architecture has been implemented in the state-of-the-art SMT solver cvc5. We evaluate its proofs for SMT-LIB benchmarks and show the new architecture allows better coverage than previous approaches, has acceptable performance overhead, and allows detailed proofs for most solving components. |
| 11:00 | Seventeen Provers under the Hammer PRESENTER: Martin Desharnais ABSTRACT. One of the main success stories of automatic theorem provers has been their integration into proof assistants. Such integrations, or “hammers,” increase proof automation and hence user productivity. In this paper, we use the Sledgehammer tool of Isabelle/HOL to find out how useful modern provers are at proving formulas of higher-order logic. Our evaluation follows in the steps of Böhme and Nipkow’s Judgment Day study from 2010, but instead of three provers we use 17, including SMT solvers and higher-order provers. Our work offers an alternative yardstick for comparing modern provers, next to the benchmarks and competitions emerging from the TPTP World and SMT-LIB. |
| 11:30 | The Isabelle ENIGMA PRESENTER: Zarathustra Goertzel ABSTRACT. We significantly improve the performance of the E automated theorem prover on the Isabelle Sledgehammer problems by combining learning and theorem proving in several ways. In particular, we develop targeted versions of the ENIGMA guidance for the typed Isabelle problems, targeted versions of neural premise selection, and targeted strategies for E. The methods are trained in several iterations over hundreds of thousands untyped and typed first-order problems extracted from Isabelle, leading to a large improvement of the automation both in the typed and untyped setting. |
| 12:00 | Automatic Test-Case Reduction in Proof Assistants: A Case Study in Coq PRESENTER: Jason Gross ABSTRACT. As the adoption of proof assistants increases, there is a need for efficiency in identifying, documenting, and fixing compatibility issues that arise from proof assistant evolution. We present the Coq Bug Minimizer, a tool for *reproducing buggy behavior* with *minimal* and *standalone* files, integrated with coqbot to trigger *automatically* on Coq reverse CI failures. Our tool eliminates the overhead of having to download, set up, compile, and then explore and understand large developments: enabling Coq developers to easily obtain modular test-case files for fast experimentation. In this paper, we describe insights about how test-case reduction is different in Coq than in traditional compilers. We expect that our insights will generalize to other proof assistants. We evaluate the Coq Bug Minimizer on over 150 CI failures. Our tool succeeds in reducing failures to smaller test cases in roughly 75% of the time. The minimizer produces a fully standalone test case 89% of the time, and it is on average about one-third the size of the original test. The average reduced test case compiles in 1.25 seconds, with 75% taking under half a second. |
Lunches will be held in Taub lobby (CAV, CSF) and in The Grand Water Research Institute (DL, IJCAR, ITP).
| 12:30 | Business Meeting PRESENTER: Jean Christoph Jung |
Tool demonstrations for:
- From Spot 2.0 to Spot 2.10: What's New? (13:00-13:30)
- Capture, Analyze, Diagnose: Realizability Checking of Requirements in FRET (13:30-14:00)
| 14:00 | Specification-Guided Learning of Nash Equilibria with High Social Welfare PRESENTER: Kishor Jothimurugan ABSTRACT. Reinforcement learning has been shown to be an effective strategy for automatically training policies for challenging control problems. Focusing on non-cooperative multi-agent systems, we propose a novel reinforcement learning framework for training joint policies that form a Nash equilibrium. In our approach, rather than providing low-level reward functions, the user provides high-level specifications that encode the objective of each agent. Then, guided by the structure of the specifications, our algorithm searches over policies to identify one that provably forms an epsilon-Nash equilibrium (with high probability). Importantly, it prioritizes policies in a way that maximizes social welfare across all agents. Our empirical evaluation demonstrates that our algorithm computes equilibrium policies with high social welfare, whereas state-of-the-art baselines either fail to compute Nash equilibria or compute ones with comparatively lower social welfare. |
| 14:20 | Synthesizing Fair Decision Trees via Iterative Constraint Solving PRESENTER: Jingbo Wang ABSTRACT. Decision trees are increasingly used to make socially sensitive decisions, where they are expected to be not only accurate but also fair, but it remains a challenging task to optimize the decision tree learning algorithm for fairness in a predictable and explainable fashion. To overcome the challenge, we propose an iterative framework for choosing decision attributes, or features, at each level of the tree by formulating feature selection as a series of mixed integer optimization problems. Both fairness and accuracy requirements are encoded as numerical constraints and solved by an off-the-shelf constraint solver. As a result, the trade-off between fairness and accuracy is made quantifiable. At a high level, our constraint-based method can be viewed as a generalization of the mainstream, entropy-based, greedy search techniques (such as CART, ID3, and C4.5) and existing fair learning techniques such as IGCS and MIP. Our experimental evaluation on six datasets, where demographic parity is the fairness metric, shows that the method is significantly more effective in reducing bias while maintaining accuracy. Furthermore, compared to non-iterative constraint solving, our iterative approach is at least 10 times faster. |
| 14:40 | SMT-based Translation Validation for Machine Learning Compiler  PRESENTER: Juneyoung Lee ABSTRACT. Machine learning compilers are large software containing complex transformations for deep learning models, and any buggy transformation may cause a crash or silently bring a regression to the prediction accuracy and performance. This paper proposes an SMT-based translation validation framework for Multi-Level IR (MLIR), a compiler framework used by many deep learning compilers. It proposes an SMT encoding tailored for translation validation that is an over-approximation of the FP arithmetic and reduction operations. It performs abstraction refinement if validation fails. We also propose a new approach for encoding arithmetic properties of reductions in SMT. We found mismatches between the specification and implementation of MLIR, and validated high-level transformations for SqueezeNet, MobileNet, and text_classification with proper splitting. |
| 15:00 | Verifying Fairness in Quantum Machine Learning PRESENTER: Ji Guan ABSTRACT. Due to the beyond-classical capability of quantum computing, quantum machine learning is standing alone or being embedded in classical models for decision making, especially in the field of finance. Fairness and other ethical issues are often one of the main concerns in decision making. In this work, we define a formal framework for the fairness verification and analysis of quantum machine learning decision models, where we adopt one of the most popular notions of fairness in the literature based on the intuition --- any two similar individuals must be treated similarly and thus are unbiased. We show that quantum noise can help to improve fairness and develop an algorithm to check whether a (noisy) quantum machine learning model is fair. In particular, this algorithm can find bias kernels of quantum data (encoding individuals) during checking. These bias kernels generate infinitely many bias pairs for investigating the unfairness of the model. Our algorithm is designed based on a highly efficient data structure --- Tensor Networks --- and implemented on Google’s TensorFlow Quantum. The utility and effectiveness of our algorithm are confirmed by the experimental results, including income prediction and credit scoring on real-world data, for a class of random (noisy) quantum decision models with 27 qubits ($2^{27}$-dimensional state space) tripling ($2^{18}$ times more than) that of the state-of-the-art algorithms for verifying quantum machine learning models. |
| 15:20 | MoGym: Using Formal Models for Training and Verifying Decision-making Agents PRESENTER: Maximilian Alexander Köhl ABSTRACT. MoGym, is an integrated toolbox enabling the training and verification of machine-learned decision-making agents based on formal models, for the purpose of sound use in the real world. Given a formal representation of a decision-making problem in the JANI format and a reach-avoid objective, MoGym (a) enables training a decision-making agent with respect to that objective directly on the model using reinforcement learning (RL) techniques, and (b) it supports rigorous assessment of the quality of the induced decision-making agent by means of deep statistical model checking (DSMC). MoGym implements the standard interface for training environments established by OpenAI Gym, thereby connecting to the vast body of existing work in the RL community. In return, it makes accessible the large set of existing JANI model checking benchmarks to machine learning research. It thereby contributes an efficient feedback mechanism for improving in particular reinforcement learning algorithms. The connective part is implemented on top of Momba. For the DSMC quality assurance of the learned decision-making agents, a variant of the statistical model checker modes of the Modest Toolset is leveraged, which has been extended by two new resolution strategies for non-determinism when encountered during statistical evaluation. |
| 14:00 | Legendre PRF (Multiple) Key Attacks and the Power of Preprocessing PRESENTER: Floyd Zweydinger ABSTRACT. Due to its amazing speed and multiplicative properties the Legendre PRF recently finds widespread applications e.g. in Ethereum 2.0, multiparty computation and in the quantum-secure signature proposal LegRoast. However, its security is not yet extensively studied. The Legendre PRF computes for a key $k$ on input $x$ the Legendre symbol $L_k(x) = \left( \frac {x+k} {p} \right)$ in some finite field $\F_p$. As standard notion, PRF security is analysed by giving an attacker oracle access to $L_k(\cdot)$. Khovratovich's collision-based algorithm recovers $k$ using $L_k(\cdot)$ in time $\sqrt{p}$ with constant memory. It is a major open problem whether this birthday-bound complexity can be beaten. We show a somewhat surprising wide-ranging analogy between the discrete logarithm problem and Legendre symbol computations. This analogy allows us to adapt various algorithmic ideas from the discrete logarithm setting. More precisely, we present a small memory multiple-key attack on $m$ Legendre keys $k_1, \ldots, k_m$ in time $\sqrt{mp}$, i.e. with amortized cost $\sqrt{p/m}$ per key. This multiple-key attack might be of interest in the Ethereum context, since recovering many keys simultaneously maximizes an attacker's profit. Moreover, we show that the Legendre PRF admits precomputation attacks, where the precomputation depends on the public $p$ only -- and not on a key $k$. Namely, an attacker may compute e.g. in precomputation time $p^{\frac 2 3}$ a hint of size $p^{\frac 1 3}$. On receiving access to $L_k(\cdot)$ in an online phase, the attacker then uses the hint to recover the desired key $k$ in time only $p^{\frac 1 3}$. Thus, the attacker's online complexity again beats the birthday-bound. In addition, our precomputation attack can also be combined with our multiple-key attack. We explicitly give various tradeoffs between precomputation and online phase. E.g. for attacking $m$ keys one may spend time $mp^{\frac 2 3}$ in the precomputation phase for constructing a hint of size $m^2 p^{\frac 1 3}$. In an online phase, one then finds {\em all $m$ keys in total time} only $p^{\frac 1 3}$. Precomputation attacks might again be interesting in the Ethereum 2.0 context, where keys are frequently changed such that a heavy key-independent precomputation pays off. |
| 14:30 | A Complete Characterization of Security for Linicrypt Block Cipher Modes PRESENTER: Lawrence Roy ABSTRACT. We give characterizations of IND$-CPA security for a large, natural class of encryption schemes. Specifically, we consider encryption algorithms that invoke a block cipher and otherwise perform linear operations (e.g., XOR and multiplication by fixed field elements) on intermediate values. This class of algorithms corresponds to the Linicrypt model of Carmer & Rosulek (Crypto 2016). Our characterization for this class of encryption schemes is sound but not complete. We then focus on a smaller subclass of block cipher modes, which iterate over the blocks of the plaintext, repeatedly applying the same Linicrypt program. For these Linicrypt block cipher modes, we are able to give a sound and complete characterization of IND$-CPA security. Our characterization is linear-algebraic in nature and is easy to check for a candidate mode. Interestingly, we prove that a Linicrypt block cipher mode is secure if and only if it is secure against adversaries who choose all-zeroes plaintexts. |
| 15:00 | Locked Circuit Indistinguishability: A Notion of Security for Logic Locking PRESENTER: Mohamed Elmassad ABSTRACT. We address logic locking, a mechanism for securing digital Integrated Circuits (ICs) from piracy by untrustworthy foundries. We discuss previous work and the state-of-the-art, and observe that, despite more than a decade of research that has gone into the topic (resulting in both powerful attacks and subsequent defenses), there is no consensus on what it means for a particular locking mechanism to be secure. This paper attempts to remedy this situation. Specifically, it formulates a definition of security for a logic locking mechanism based on indistinguishability and relates the definition to security from actual attackers in a precise and unambiguous manner. We then describe a mechanism that satisfies the definition, thereby achieving (provable) security from all prior attacks. The mechanism assumes the existence of both a puncturable pseudorandom function family and an indistinguishability obfuscator, two cryptographic primitives that exist under well-founded assumptions. The mechanism builds upon the Stripped-Functionality Logic Locking (SFLL) framework, a state-of-the-art family of locking mechanisms whose potential for ever achieving security is currently in question. Along the way, partly as motivation, we present additional results, such as a reason founded in average-case complexity for why benchmark circuits locked with a prior scheme are susceptible to the well-known SAT attack against such schemes, and why provably thwarting the SAT attack is insufficient as a meaningful notion of security for logic locking. |
| 14:00 | Using Automated Reasoning Techniques for Enhancing the Efficiency and Security of (Ethereum) Smart Contracts PRESENTER: Elvira Albert |
| 15:00 | Guiding an Automated Theorem Prover with Neural Rewriting PRESENTER: Jelle Piepenbrock ABSTRACT. Automated theorem provers (ATPs) are today used to attack open problems in several areas of mathematics. An ongoing project by Kinyon and Veroff uses Prover9 to search for the proof of the Abelian Inner Mapping (AIM) Conjecture, one of the top open conjectures in quasigroup theory. In this work, we improve Prover9 on a benchmark of AIM problems by neural synthesis of useful alternative formulations of the goal. In particular, we design the 3SIL (stratified shortest solution imitation learning) method. 3SIL trains a neural predictor through a reinforcement learning (RL) loop to propose correct rewrites of the conjecture that guide the search. 3SIL is first developed on a simpler, Robinson arithmetic rewriting task for which the reward structure is similar to theorem proving. There we show that 3SIL outperforms other RL methods. Next we train 3SIL on the AIM benchmark and show that the final trained network, deciding what actions to take within the equational rewriting environment, proves 70.2% of problems, outperforming Waldmeister (65.5%). When we combine the rewrites suggested by the network with Prover9, we prove 8.3% more theorems than Prover9 in the same time, bringing the performance of the combined system to 90% |
| 14:00 | Use and abuse of instance parameters in the Lean mathematical library ABSTRACT. The Lean mathematical library mathlib features extensive use of the typeclass pattern for organising mathematical structures, based on Lean’s mechanism of instance parameters. Related mechanisms for typeclasses are available in other provers including Agda, Coq and Isabelle with varying degrees of adoption. This paper analyses representative examples of design patterns involving instance parameters in the current Lean 3 version of mathlib, focussing on complications arising at scale and how the mathlib community deals with them. |
| 14:30 | The Zoo of Lambda-Calculus Reduction Strategies, and Coq PRESENTER: Tomasz Drab ABSTRACT. We present a generic framework for the specification and reasoning about reduction strategies in the lambda calculus representable as sets of term decompositions. It is provided as a Coq formalization that features a novel format of {\em phased} strategies. It facilitates concise description and algebraic reasoning about properties of reduction strategies. The formalization accommodates many well-known strategies, both weak and strong, such as call by name, call by value, head reduction, normal order, full $\beta$-reduction, etc. We illustrate the use of the framework as a tool to inspect and categorize the ``zoo'' of existing strategies, as well as to discover and study new ones with particular properties. |
| 15:00 | Formalizing the set of primes as an alternative to the DPRM theorem (short paper) PRESENTER: Cezary Kaliszyk ABSTRACT. The DPRM (Davis-Putnam-Robinson-Matiyasevich) theorem is the main step in the negative resolution of Hilbert's 10th problem. Almost three decades of work on the problem have resulted in several equally surprising results. These include the existence of more refined diophantine equations with a reduced number of variables, as well as the explicit construction of polynomials that represent specific sets, in particular the set of primes. In this work, we formalize these constructions in the Mizar system. We focus on the set of prime numbers and its explicit representation using 10 variables. It is the smallest representation known today. This formalization is the next step in the research on formal approaches to diophantine sets following the DPRM theorem. |
| 16:00 | Synthesis and Analysis of Petri Nets from Causal Specifications ABSTRACT. Petri nets are one of the most prominent system-level formalisms for the specification of causality in concurrent, distributed, or multi-agent systems. This formalism is abstract enough to be analyzed using theoretical tools, and at the same time, concrete enough to eliminate ambiguities that would arise at implementation level. One interesting feature of Petri nets is that they can be studied from the point of view of true concurrency, where causal scenarios are specified using partial orders, instead of approaches based on interleaving. On the other hand, message sequence chart (MSC) languages, are a standard formalism for the specification of causality from a purely behavioral perspective. In other words, this formalism specifies a set of causal scenarios between actions of a system, without providing any implementation-level details about the system. In this work, we establish several new connections between MSC languages and Petri nets, and show that several computational problems involving these formalisms are decidable. Our results settle some open problems that had been open for several years. To obtain our results we develop new techniques in the realm of slice automata theory, a framework introduced one decade ago in the study of the partial order behavior of bounded Petri nets. These techniques can also be applied to establish connections between Petri nets and other well-studied behavioral formalisms, such as the notion of Mazurkiewicz trace languages. |
| 16:20 | Verifying generalised and structural soundness of workflow nets via relaxations PRESENTER: Philip Offtermatt ABSTRACT. Workflow nets are a well-established mathematical formalism for the analysis of business processes arising from either modeling tools or process mining. The central decision problems for workflow nets are k-soundness, generalised soundness and structural soundness. Most existing tools focus on k-soundness. In this work, we propose novel scalable semi-procedures for generalised and structural soundness. This is achieved via integral and continuous Petri net reachability relaxations. We show that our approach is competitive against state-of-the-art tools. |
| 16:40 | Capture, Analyze, Diagnose: Realizability Checking of Requirements in FRET PRESENTER: Andreas Katis ABSTRACT. Requirements formalization has become increasingly popular in industrial settings as an effort to disambiguate designs and optimize development time and costs for critical system components. Formal requirements elicitation also enables the employment of analysis tools to prove important properties, such as consistency and realizability. In this paper, we present the realizability analysis framework that we developed as part of the Formal Requirements Elicitation Tool (FRET). Our framework prioritizes usability, and employs state-of-the-art analysis algorithms that support infinite theories. We demonstrate the workflow for realizability checking, showcase the diagnosis process that supports visualization of conflicts between requirements and simulation of counterexamples, and discuss results from industrial-level case studies. |
| 16:50 | Information Flow Guided Synthesis PRESENTER: Niklas Metzger ABSTRACT. Compositional synthesis relies on the discovery of assumptions, i.e., restrictions on the behavior of the remainder of the system that allow a component to realize its specification. In order to avoid losing valid solutions, these assumptions should be necessary conditions for realizability. However, because there are typically many different behaviors that realize the same specification, necessary behavioral restrictions often do not exist. In this paper, we introduce a new class of assumptions for compositional synthesis, which we call information flow assumptions. Such assumptions capture an essential aspect of distributed computing, because components often need to act upon information that is available only in other components. The presence of a certain flow of information is therefore often a necessary requirement, while the actual behavior that establishes the information flow is unconstrained. In contrast to behavioral assumptions, which are properties of individual computation traces, information flow assumptions are hyperproperties, i.e., properties of sets of traces. We present a method for the automatic derivation of information-flow assumptions from a temporal logic specification of the system. We then provide a technique for the automatic synthesis of component implementations based on information flow assumptions. This provides a new compositional approach to the synthesis of distributed systems. We report on encouraging first experiments with the approach, carried out with the BoSyHyper synthesis tool. |
| 17:10 | Randomized Synthesis for Diversity and Cost Constraints with Control Improvisation PRESENTER: Andreas Gittis ABSTRACT. In many synthesis problems, it can be essential to generate implementations which not only satisfy functional constraints but are also randomized to improve variety, robustness, or unpredictability. The recently-proposed framework of control improvisation (CI) provides techniques for the correct-by-construction synthesis of randomized systems subject to hard and soft constraints. However, prior work on CI has focused on qualitative specifications, whereas in robotic planning and other areas we often have quantitative quality metrics which can be traded against each other. For example, a designer of a patrolling security robot might want to know by how much the average patrol time needs to be increased in order to ensure that a particular aspect of the robot's route is sufficiently diverse and hence unpredictable. In this paper, we enable this type of application by generalizing the CI problem to support quantitative soft constraints which bound the expected value of a given cost function, and randomness constraints which enforce diversity of the generated traces with respect to a given label function. We establish the basic theory of labelled quantitative CI problems, and develop efficient algorithms for solving them when the specifications are encoded by finite automata. We also provide an approximate improvisation algorithm based on constraint solving for any specifications encodable as Boolean formulas. We demonstrate the utility of our problem formulation and algorithms with experiments applying them to generate diverse near-optimal plans for robotic planning problems. |
| 16:00 | Prophecy Variables for Hyperproperty Verification PRESENTER: Raven Beutner ABSTRACT. Temporal logics for hyperproperties like HyperLTL use trace quantifiers to express properties that relate multiple system runs. In practice, the verification of such specifications is mostly limited to formulas without quantifier alternation, where verification can be reduced to checking a trace property over the self-composition of the system. Quantifier alternations like $\forall \pi. \exists \pi'. \phi$, can either be solved by complementation or with an interpretation as a two-person game between a $\forall$-player, who incrementally constructs the trace $\pi$, and an $\exists$-player, who constructs $\pi'$ in such a way that $\pi$ and $\pi'$ together satisfy $\phi$. The game-based approach is significantly cheaper but incomplete because the $\exists$-player does not know the future moves of the $\forall$-player. In this paper, we establish that the game-based approach can be made complete by adding ($\omega$-regular) temporal prophecies. Our proof is constructive, yielding an effective algorithm for the generation of a complete set of prophecies. |
| 16:30 | Mapping Synthesis for Hyperproperties PRESENTER: Tzu-Han Hsu ABSTRACT. In system design, high-level system models typically need to be mapped to an execution platform (e.g., hardware, environment, compiler, etc). The platform may naturally strengthen some constraints or weaken some others, but it is expected that the low-level implementation on the platform should preserve all the functional and extra-functional properties of the model, including the ones for information-flow security. It is, however, well known that simple notions of refinement do not preserve information-flow security properties. In this paper, we propose a novel automated mapping synthesis approach that preserves hyperproperties expressed in the temporal logic HyperLTL. The significance of our technique is that it can handle formulas with quantifier alternations, which is typically the source of difficulty in refinement for informationflow security policies. We reduce the mapping synthesis problem to HyperLTL model checking and leverage recent efforts in bounded model checking for hyperproperties. We demonstrate how mapping synthesis can be used in various applications, including enforcing non-interference and automating secrecy-preserving refinement mapping. We also evaluate our approach using the battleship game and password validation use cases. |
| 16:00 | Non-associative, non-commutative multi-modal linear logic PRESENTER: Stepan Kuznetsov ABSTRACT. Adding multi-modalities (called subexponentials) to linear logic enhances its power as a logical framework, which has been extensively used in the specification of e.g. proof systems, programming languages and bigraphs. Initially, subexponentials allowed for classical, linear, affine or relevant behaviors. Recently, this framework was enhanced so to allow for commutativity as well. In this work, we close the cycle by considering associativity. We show that the resulting system (acLL) admits the (multi)cut rule, and we prove two undecidability results for fragments/variations of acLL. |
| 16:20 | Paraconsistent Gödel modal logic PRESENTER: Daniil Kozhemiachenko ABSTRACT. We introduce a~paraconsistent modal logic $\KGsquare$, based on Gödel logic with coimplication (bi-Gödel logic) expanded with a De Morgan negation $\neg$. We use the logic to formalise reasoning with graded, incomplete and inconsistent information. Semantics of $\KGsquare$ is two-dimensional: we interpret $\KGsquare$ on crisp frames with two valuations $v_1$ and $v_2$, connected via $\neg$, that assign to each formula two values from the real-valued interval $[0,1]$. The first (resp., second) valuation encodes the positive (resp., negative) information the state gives to a~statement. We obtain that $\KGsquare$ is strictly more expressive than the classical modal logic $\mathbf{K}$ by proving that finitely branching frames are definable and by establishing a faithful embedding of $\mathbf{K}$ into $\KGsquare$. We also construct a~constraint tableau calculus for $\KGsquare$ over finitely branching frames, establish its decidability and provide a~complexity evaluation. |
| 16:40 | Effective Semantics for the Modal Logics K and KT via Non-deterministic Matrices PRESENTER: Yoni Zohar ABSTRACT. A four-valued semantics for the modal logic K is introduced. Possible worlds are replaced by a hierarchy of four-valued valuations, where the valuations of the first level correspond to valuations that are legal w.r.t. a basic non-deterministic matrix, and each level further restricts its set of valuations. The semantics is proven to be effective, and to precisely capture derivations in a sequent calculus for K of a certain form. Similar results are then obtained for the modal logic KT, by simply deleting one of the truth values. |